External Data Plugin¶
You can easily apply standardized test cases across a wide range of features to significantly reduce redundant data for large test suites. By reusing execution flows, you can also speed up exploratory and approval testing for ranges of examples. SpecFlow makes all of this possible by introducing support for loading external data into scenarios easily.
The SpecFlow ExternalData plugin lets teams separate test data from test scenarios, and reuse examples across a large set of scenarios. This is particularly helpful when a common set of examples needs to be consistently verified in different scenarios.
Simply download the NuGet package and add it to your specflow projects to use it.
Supported Data Sources¶
CSV files (format ‘CSV’, extension .csv)
> Note: Standard RFC 4180 CSV format is supported with a header line (plugin uses CsvHelper to parse the files).
Excel files (format Excel, extensions .xlsx, .xls, .xlsb)
> Note: Both XLSX and XLS is supported (plugin uses ExcelDataReader to parse the files).
Examples¶
CSV files¶
The below examples all use the same products.csv file. The file contains three products and their corresponding prices:
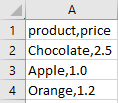
This scenario will be treated as a scenario outline with the products from the CSV file replacing the <product
> parameter in the given statement:
@DataSource:products.csv
Scenario: Valid product prices are calculated
Given the customer has put 1 piece of <product> in the basket
When the basket price is calculated
Then the basket price should be greater than zero
This scenario will be treated as a scenario outline similar to the above example but uses both <product
> and <price> from the CSV file:
@DataSource:products.csv
Scenario: The basket price is calculated correctly
Given the price of <product> is €<price>
And the customer has put 1 pcs of <product> to the basket
When the basket price is calculated
Then the basket price should be €<price>
This scenario shows how you can extend the product list using the example table with the ones from the CSV file. A total of 4 products will be added here, 3 from the CSV file plus “Cheesecake” from the example table:
@DataSource:products.csv
Scenario Outline: Valid product prices are calculated (Outline)
Given the customer has put 1 pcs of <product> to the basket
When the basket price is calculated
Then the basket price should be greater than zero
Examples:
| product |
| Cheesecake |
You may also add the @DataSource above the example table if you wish to:
Scenario Outline: Valid product prices are calculated (Outline, example annotation)
Given the customer has put 1 pcs of <product> to the basket
When the basket price is calculated
Then the basket price should be greater than zero
@DataSource:products.csv
Examples:
| product |
| Cheesecake |
In this scenario the parameters names do not match the column names in the CSV file but we can address that by using the
@DataField:product-name=productand@DataField:price-in-EUR=pricetags:
@DataSource:products.csv @DataField:product-name=product @DataField:price-in-EUR=price
Scenario: The basket price is calculated correctly (renamed fields)
Given the price of <product-name> is €<price-in-EUR>
And the customer has put 1 piece of <product-name> in the basket
When the basket price is calculated
Then the basket price should be €<price-in-EUR>
This scenario is similar to the above scenario with the renaming of the parameters, but the difference is the use of space in the parameter name. Spaces are not supported and must be replaced with underscore (_):
@DataSource:products.csv @DataField:product_name=product @DataField:price-in-EUR=price
Scenario: The basket price is calculated correctly
Given the customer has put 1 piece of <product name> in the basket
When the basket price is calculated
Then the basket price should be greater than zero
Examples:
| product name |
| Cheesecake |
Excel files¶
You can use Excel files the same way as you do with CSV files with some minor differences:
Only simple worksheets are supported, where the header is in the first row and the data comes right below that. Excel files that contain tables, graphics, etc. are not supported.
Excel files with multiple worksheets are supported, you can use the
@DataSet:sheet-nameto select the worksheets you wish to target. The plugin uses the first worksheet by default.Use underscores in the
@DataSettag instead of spaces if the worksheet name contains spaces.
The below example shows an Excel file with multiple worksheets and we wish to target the last worksheet labelled “other products”. We do this by using the @DataSet:other_products tag. Note the use of (_) instead of space:
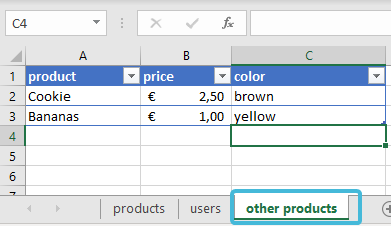
@DataSource:products.xlsx @DataSet:other_products
Scenario: The basket price is calculated correctly for other products
Given the price of <product> is €<price>
And the customer has put 1 piece of <product> in the basket
When the basket price is calculated
Then the basket price should be €<price>
Language Settings¶
The decimal and date values read from an Excel file will be exported using the language of the feature file (specified using the #language setting in the feature file or in the SpecFlow configuration file). This setting affects for example the decimal operator as in some countries comma (,) is used as decimal separator instead of dot (.). To specify not only the language but also the country use the #language: language-country tag, e.g. #language: de-AT for Deutsch-Austria.
Example: Hungarian uses comma (,) as decimal separator instead of dot (.), so SpecFlow will expect the prices in format 1,23:
This sample shows that the language settings are applied for the data that is being read by the external data plugin.
#language: hu-HU
Jellemző: External Data from Excel file (Hungarian)
@DataSource:products.xlsx
Forgatókönyv: The basket price is calculated correctly
Amennyiben the price of <product> is €<price>
És the customer has put 1 pcs of <product> to the basket
Amikor the basket price is calculated
Akkor the basket price should be €<price>